
Grupa programera iz britanske kompanije za razvoj umjetne inteligencije dizajnirala je samouke “agente” dovoljno vješte da u slavnoj multiplayer videoigri Quake III Arena razvale i posrame običnu, ali ne i profesionalnu ljudsku konkurenciju.
Rad znanstvenika “DeepMinda”, kompanije u vlasništvu Alphabeta (iliti Googlea), objavljen u četvrtak u žurnalu “Science” predstavlja prekretnicu u razvoju samouke umjetne inteligencije. Naime, za razliku od dosadašnjih nadmetanja AI-a i ljudi (u šahu, Starcraftu ili Go-u), Quake III uključuje timski rad, strateško promišljanje i interakciju unutar složenog okoliša.
“Inicijalno, oni nisu znali ništa o svijetu, radili su totalno nasumične stvari i bezglavo poskakivali uokolo,”
Tabula rasa
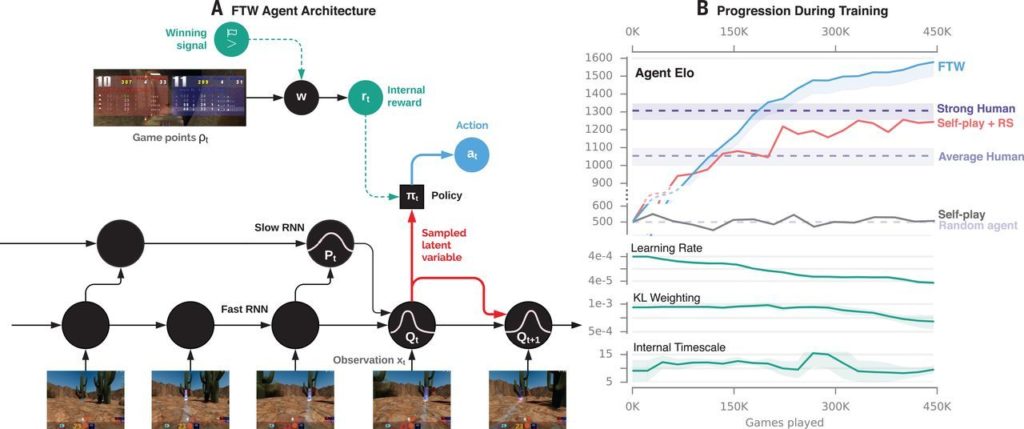
Lider istraživanja Max Jaderberg kaže da je kao testni poligon za uvježbavanje agenata poslužila modificirana inačica Quake III Arene, igre iz 1999. godine koja i danas uživa kultni status. Parovi AI agenata su prvo odigrali (simulirali) 450,000 mečeva (što odgovara četverogodišnjem neprestanom igranju) i sami sebe naučili manevriranju kroz razine, izbjegavanju ili napadanju protivnika. Oni su bili ograničeni istim pravilima kao i ljudi, učivši kroz tupavu ali učinkovitu metodu pokušaja i pogrešaka.
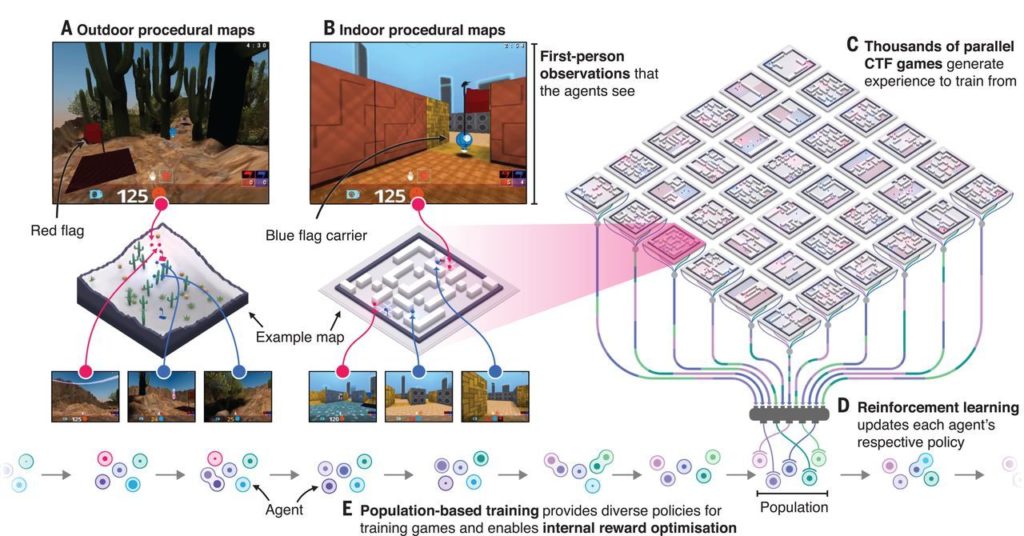
Kad su sazrjeli za okršaj, istraživači su im pridružili 40 svakodnevnih gamera koji nisu znali jesu li članovi njihova tima “botovi” ili ne. Turniri su pokazali očitu nadmoć AI-a, bili oni prepušteni sebi ili upareni s ljudima.
“Čak i nakon 12 sati prakse, ljudski timovi su pobjeđivali u samo 25 posto mečeva protiv timova s agentima,” navodi se u istraživanju. Taj se omjer nije značajno promijenio niti kad su znanstvenici usporili vrijeme reakcije i umanjili preciznost AI-a.
“Inicijalno, oni nisu znali ništa o svijetu, radili su totalno nasumične stvari i bezglavo poskakivali uokolo,” rekao je Jaderberg za AFP opisujući proces “ojačanog učenja” (RL wiki) koji je agentima podario “pamet”.
>>>Prvi AI whisky je mješavina ‘vanilije s finim notama hrasta, voća s limunom i kruškom…’
AI je dobio programersku dozvolu da sam sebe nagrađuje za “hvatanje zastave” (jednog od modaliteta gameplaya u multiplayer igrama), ali i za iznalaženje novih i inovativnih metoda hvatanja. “Jedan od doprinosa istraživanja je u tome što svaki agent uči svoj interni signal za nagradu,” kaže Jaderbeg i pojašnjava da je to agentima omogućilo da “sami odlučuju” hoće li krenuti prema zastavi, u pomoć prijateljima ili u napad na neprijatelja, odnosno da simuliraju timsku, ofanzivnu i defanzivnu igru.
“Brzo i sporo razmišljanje”
DeepMind je razvio i novu arhitekturu s “dvije vremenske linije” koju Jaderberg povezuje s knjigom “Brzo i sporo razmišljanje” (Thinking Fast and Slow) primijenjenom na AI. “Imate jedan dio agenta koji udara jako brzo, on svoja uvjerenja osvježava jako brzo i imate njegov drugi dio koji navedeno čini u sporijem tempu. Ta dva uvjerenja utječu jedno na drugo i oblikuju način na koji agent uči o svijetu,” rekao je Jaderberg.
Konačno i za istraživanje ključno, agenti su sa svakim novim mečom bili prisiljeni učiti unutar nasumično generiranih mapa. “To je značilo da rješenja agenata moraju biti generalna – oni nisu jednostavno mogli memorizirati slijed akcija,” dodao je koautor studije Wojciech Czarnecki.
Istraživanje je utvrdilo i da agenti puno brže uče u timu nego pojedinačno.
Iako većina izvještaja o istraživanju navodi da je AI potukao i posramio gamere, IEEE Spectrum piše da su dvojica profesionalnih igrača Quakea nakon šest sati razvalili i posramili agente na jednoj od složenijih i zahtjevnijih mapa.
Science 31 May 2019:
Vol. 364, Issue 6443, pp. 859-865
DOI: 10.1126/science.aau6249
Grabancijaš djeluje s integritetom, neovisnošću i slobodom od pristranosti.